


A Summary of LLM Post-Training Techniques
Why fine-tuning, reinforcement learning, and test-time scaling are essential to turning language models into useful agents.

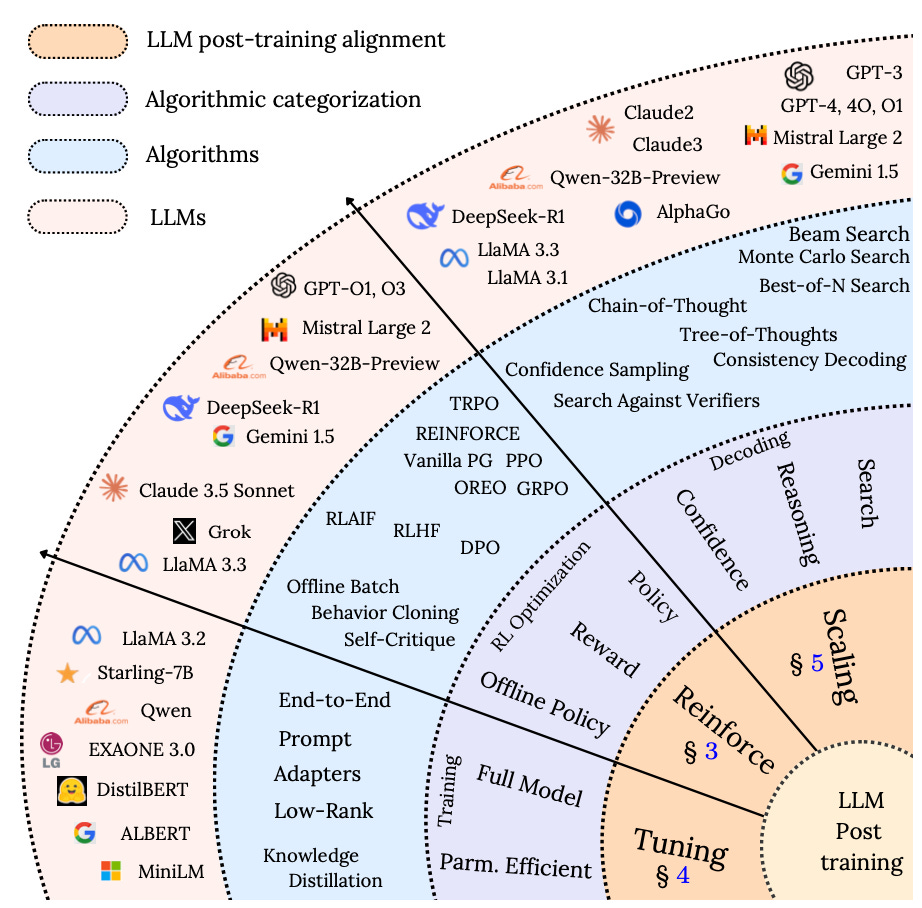
Fig1: Taxonomy of post training methods taken from LLM Post-Training: A Deep Dive into Reasoning Large Language Models”
Introduction: The Foundation and the Fine-Tuning
This post is based on insights from the recent survey “LLM Post-Training: A Deep Dive into Reasoning Large Language Models”, which organizes and explains the landscape of post-training techniques. I’ve distilled the core methodologies from the paper into this concise summary to make the concepts more accessible for practitioners and builders.
Large Language Models (LLMs) have transformed what machines can do with text. They can write, summarize, translate, and even reason to a degree. But raw pretraining, even on trillions of tokens, is only the beginning.
Post-training is where LLMs gain purpose: the ability to align with human goals, specialize in domains, and generate trustworthy outputs. This “second phase” includes fine-tuning, reinforcement learning, and smart techniques applied at inference time to push performance without retraining the model.
Why Post-Training is Essential for Your AI Applications
Pretrained models are generalists; they're “trained on everything,” but often confused by specifics. Without post-training:
They hallucinate facts
Fail to follow instructions
Ignore ethical and safety boundaries
Struggle with complex, multi-step reasoning
Post-training solves these problems by:
Aligning the model with human preferences
Specializing in tasks or domains
Boosting reasoning and factuality
Making smaller models act smarter via test-time enhancements
If pretraining is learning language, post-training is learning usefulness.
Key Post-Training Methodologies Explained
We group post-training into three big buckets:
Fine-Tuning: Specializes the model using curated data.
Test-Time Scaling (TTS): Boosts performance during inference
Reinforcement Learning (RL): Aligns behavior using feedback signals
Each approach solves different challenges, and together, they unlock powerful capabilities.
Looking Ahead: The Evolving Landscape of Post-Training
The future of post-training is rich and experimental. We're already seeing:
AI feedback replacing human feedback (RLAIF, Constitutional AI)
Search-based reasoning (ToT, Graph-of-Thoughts)
Self-critiquing and refinement loops for continuous output polishing
Inference-level intelligence replacing brute-force scaling
The real magic now lies not in growing models, but in teaching them how to think better.
Conclusion
The best AI models today aren’t just big. They’re well-refined. Post-training is how we bridge the gap between raw capabilities and trustworthy, helpful, aligned agents.
Mastering the post-training stack is essential whether you're building a customer assistant, a reasoning agent, or a specialized chatbot.
It’s not about more data. It’s about smarter training.